This is a brief tutorial on developing a digit recognizer using CNN and MNIST Data. The accompanying notebook can be found here.
Define the problem
The goal here is to correctly identify digits from a dataset of tens of thousands of handwritten images. The MNIST dataset is used for training and testing.
Before going forward, the necessary modules need to be imported.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| # data analysis
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='white', context='notebook', palette='deep')
# machine learning
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import itertools
#import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical # convert to one-hot-encoding
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ReduceLROnPlateau
# utils
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
|
Acquire the data
The MNIST data can be loaded using Keras.
1
2
3
| # Load the data
from tensorflow.keras.datasets import mnist
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
|
1
2
3
4
| # Plot some examples
for i in range(9):
plt.subplot(3,3,i+1)
plt.imshow(X_train[i], cmap=plt.get_cmap('gray'));
|
Prepare the data
Data Overview
1
2
3
| print('Train: X=%s, y=%s' %(X_train.shape, Y_train.shape))
print('Test: X=%s, y=%s' %(X_test.shape, Y_test.shape))
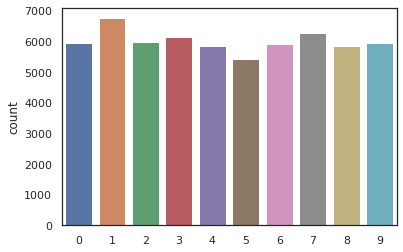
sns.countplot(Y_train);
|
1
2
| Train: X=(60000, 28, 28), y=(60000,)
Test: X=(10000, 28, 28), y=(10000,)
|
The training dataset contains 60000 examples, while the test dataset contains 10000 exmpales. Each example is a 28x28 pixels figure. In addition, we have simlar counts for the 10 digits.
Normalization
1
2
3
| # Normalize the data
X_train = X_train / 255.0
X_test = X_test / 255.0
|
1
2
3
| # Encode lables to one hot vectors (ex: 2 -> [0,0,1,0,0,0,0,0,0,0])
Y_train = to_categorical(Y_train, num_classes = 10)
Y_test = to_categorical(Y_test, num_classes = 10)
|
Reshape the data
1
2
| X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)) # X_train shape M (number of samples) x H (Height) x W (Width) x D (Depth)
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
|
Split the dataset
1
| X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size = 0.1)
|
Define the model
We use the Keras API to build a Convolutional Neural Network model to reconginze the digits in the figures.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # Set the CNN model
# In -> Conv2D -> relu -> MaxPool2D -> Conv2D -> relu -> Conv2D -> relu -> MaxPool2D -> Flatten -> Dense -> Dense -> Out
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)))
model.add(MaxPool2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform'))
model.add(MaxPool2D((2, 2)))
model.add(Flatten())
model.add(Dense(100, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(10, activation='softmax'))
#opt = Adam(lr=0.01)
opt = SGD(lr=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
conv2d_2 (Conv2D) (None, 9, 9, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 100) 102500
_________________________________________________________________
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 159,254
Trainable params: 159,254
Non-trainable params: 0
_________________________________________________________________
|
Train the model
1
| history = model.fit(X_train, Y_train, epochs=10, batch_size=32, validation_data=(X_val, Y_val), verbose =1)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| Epoch 1/10
1688/1688 [==============================] - 28s 17ms/step - loss: 0.1290 - accuracy: 0.9600 - val_loss: 0.0554 - val_accuracy: 0.9815
Epoch 2/10
1688/1688 [==============================] - 28s 16ms/step - loss: 0.0440 - accuracy: 0.9863 - val_loss: 0.0485 - val_accuracy: 0.9850
Epoch 3/10
1688/1688 [==============================] - 28s 16ms/step - loss: 0.0289 - accuracy: 0.9906 - val_loss: 0.0393 - val_accuracy: 0.9878
Epoch 4/10
1688/1688 [==============================] - 28s 16ms/step - loss: 0.0205 - accuracy: 0.9933 - val_loss: 0.0306 - val_accuracy: 0.9908
Epoch 5/10
1688/1688 [==============================] - 30s 18ms/step - loss: 0.0155 - accuracy: 0.9952 - val_loss: 0.0356 - val_accuracy: 0.9907
Epoch 6/10
1688/1688 [==============================] - 32s 19ms/step - loss: 0.0117 - accuracy: 0.9962 - val_loss: 0.0362 - val_accuracy: 0.9903
Epoch 7/10
1688/1688 [==============================] - 35s 20ms/step - loss: 0.0083 - accuracy: 0.9974 - val_loss: 0.0381 - val_accuracy: 0.9910
Epoch 8/10
1688/1688 [==============================] - 35s 21ms/step - loss: 0.0063 - accuracy: 0.9982 - val_loss: 0.0305 - val_accuracy: 0.9920
Epoch 9/10
1688/1688 [==============================] - 35s 21ms/step - loss: 0.0055 - accuracy: 0.9982 - val_loss: 0.0333 - val_accuracy: 0.9920
Epoch 10/10
1688/1688 [==============================] - 36s 21ms/step - loss: 0.0032 - accuracy: 0.9990 - val_loss: 0.0366 - val_accuracy: 0.9918
|
The training accuracy is 0.9990, and the validation accuracy is 0.9918.
1
2
| # Save the model
model.save('cnn_model.h5')
|
Evulate the model
1
2
| # predict results
loss, accuracy = model.evaluate(X_test, Y_test, verbose=1)
|
1
| 313/313 [==============================] - 2s 5ms/step - loss: 0.0325 - accuracy: 0.9919
|
The accuracy on the test dataset is 0.9919.
1
2
3
4
5
6
7
8
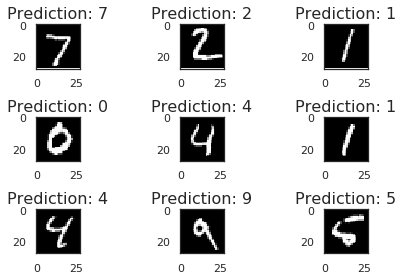
| # Show the first few predictions
for i in range(9):
ax = plt.subplot(3,3,i+1)
results = model.predict(X_test[i:i+1,:,:,:])
plt.tight_layout()
predicted_digit = np.argmax(results, axis = 1)
plt.imshow(X_test[i,:,:,0],cmap=plt.get_cmap('gray'));
ax.set_title("Prediction: %s" %predicted_digit[0],fontsize=16)
|
References
This tutorial has been created based on great work done solving this digit recognizer problem.
- https://machinelearningmastery.com/how-to-develop-a-convolutional-neural-network-from-scratch-for-mnist-handwritten-digit-classification/
- https://www.kaggle.com/yassineghouzam/introduction-to-cnn-keras-0-997-top-6

Comments powered by Disqus. Accept cookies to comment.